



Blog Fast White Cat
Czy rel=”canonical” wystarczy? Jak uniknąć duplicate content na stronach paginacji
admin wrz 17. 2017
Powielanie treści na różnych podstronach, w obrębie tej samej witryny jest często spotykanym błędem optymalizacyjnym.
Problem ten występuje również w branży ecommerce – jest ona wręcz szczególnie narażona, ze względu na duże rozmiary serwisów sklepów internetowych. Występującą na nich paginacje, formy sortowania, czy filtracji produktów, sprzyjające występowaniu duplikacji treści (duplicate content). Jak temu zaradzić?
Od 2009 roku Google rozpoznaje stosowanie dyrektywy rel=”canonical”, będącej sugestią dla wyszukiwarek, która podstrona jest stroną podstawową (kanoniczną), a która jej powieleniem.
W założeniu, właściwa implementacja rel=”canonical” na stronie www powinna wyeliminować problem duplikacji treści. Jednak, jak możemy przeczytać na oficjalnym blogu Google, https://support.google.com/webmasters/answer/139066
Jest to jedynie wskazówka, która może zostać zignorowana przez algorytm.
Efekt tej ignorancji: niewłaściwa indeksacja, spadek pozycji strony w wynikach wyszukiwania, spadek ruchu na stronie, może mieć nieprzyjemne konsekwencje dla sprzedaży.
Poniższy zrzut wykresu widoczności strony dla fraz w top 10 w wynikach wyszukiwania, wygenerowany w narzędziu Senuto, przedstawia sytuację, w której niepoprawne zaimplementowanie rel=”canonical” doprowadziło do spadku pozycji:
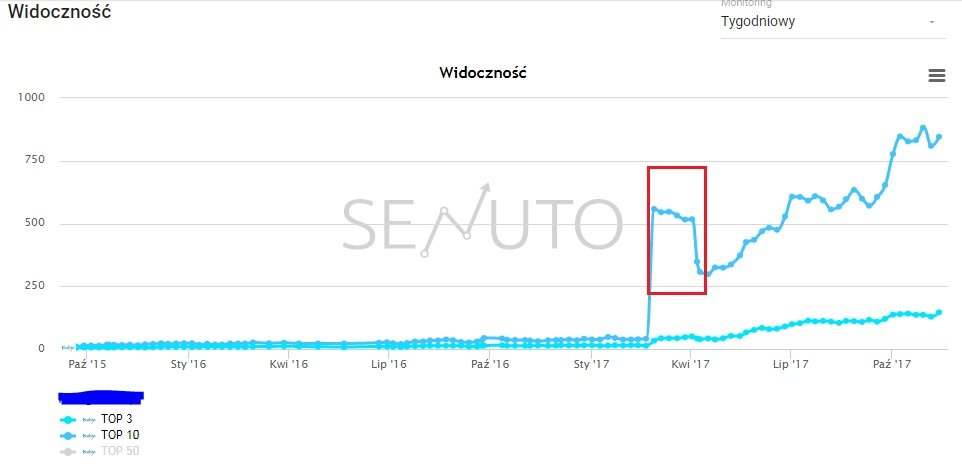
Serwis nie posiadał większych błędów optymalizacyjnych i początkowo nastąpił znaczny przyrost widoczności. Następnie zaobserwować można spadek, spowodowany wzrostem ilości zaindeksowanych podstron duplikujących treść, co skutkowało zaniżeniem oceny dla kluczowych podstron.
Powodem było zignorowanie przez algorytm Google rel=”canonical”.
Dobrą praktyką jest dodatkowe zastosowanie atrybutów rel=”next” i rel=”prev” na stronach z paginacją (https://support.google.com/webmasters/answer/1663744?hl=pl). Implementuje się je w sekcji <head></head> w kodzie strony. Wskażą one na sekwencję logiczną stron i zwiększą szansę na poprawną indeksację i wyświetlanie użytkownikom pierwszej strony.
Możemy dodatkowo zablokować wyświetlanie się treści (np. opisu kategorii) na kolejnych stronach poza pierwszą, czy ustawić na nich „noindex, follow” w meta robots lub blokując indeksację w pliku robots.txt. Dwa ostatnie rozwiązania nie są jednak preferowane, google w klarowny sposób informuje, że blokowanie dostępu robotom nie jest właściwym rozwiązaniem.
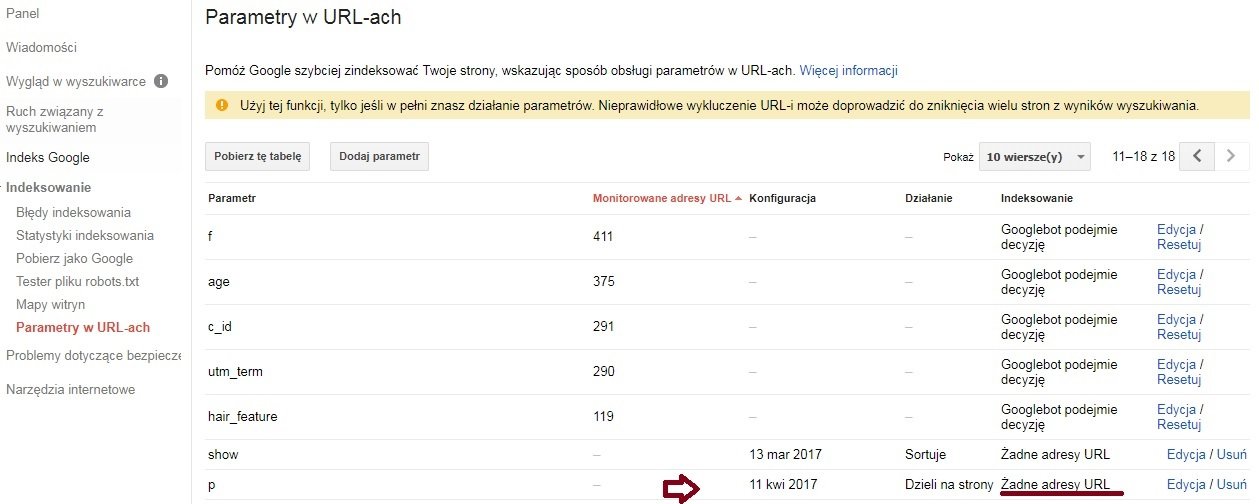
W przypadku kiedy stronicowanie, czy sortowanie oparte jest na dodawaniu parametru do adresu url, możemy takowy parametr wykluczyć z indeksacji za pomocą GSC.
Unikalna i wartościowa treść, właściwie nasycona słowami kluczowymi jest niezaprzeczalnie jednym z istotniejszych elementów przekładających się na widoczność serwisów w wynikach wyszukiwania. Google stara się dostarczyć użytkownikom najlepiej dopasowanej odpowiedzi na ich zapytanie. Treści nieunikalne, skopiowane z innych stron lub zduplikowane w obrębie serwisu mogą jedynie utrudnić indeksację i wyrzucić nasz serwis z pierwszej dziesiątki SERP.
Samo wdrożenie rel=”canonical” na stronach paginacji może okazać się niewystarczające, dlatego warto dodatkowo zastosować atrybuty rel=”next”, rel=”prev” oraz zablokować wyświetlanie się treści na kolejnych podstronach.
Problem ten występuje również w branży ecommerce – jest ona wręcz szczególnie narażona, ze względu na duże rozmiary serwisów sklepów internetowych. Występującą na nich paginacje, formy sortowania, czy filtracji produktów, sprzyjające występowaniu duplikacji treści (duplicate content). Jak temu zaradzić?
Od 2009 roku Google rozpoznaje stosowanie dyrektywy rel=”canonical”, będącej sugestią dla wyszukiwarek, która podstrona jest stroną podstawową (kanoniczną), a która jej powieleniem.
W założeniu, właściwa implementacja rel=”canonical” na stronie www powinna wyeliminować problem duplikacji treści. Jednak, jak możemy przeczytać na oficjalnym blogu Google, https://support.google.com/webmasters/answer/139066
Jest to jedynie wskazówka, która może zostać zignorowana przez algorytm.
Efekt tej ignorancji: niewłaściwa indeksacja, spadek pozycji strony w wynikach wyszukiwania, spadek ruchu na stronie, może mieć nieprzyjemne konsekwencje dla sprzedaży.
Poniższy zrzut wykresu widoczności strony dla fraz w top 10 w wynikach wyszukiwania, wygenerowany w narzędziu Senuto, przedstawia sytuację, w której niepoprawne zaimplementowanie rel=”canonical” doprowadziło do spadku pozycji:
Serwis nie posiadał większych błędów optymalizacyjnych i początkowo nastąpił znaczny przyrost widoczności. Następnie zaobserwować można spadek, spowodowany wzrostem ilości zaindeksowanych podstron duplikujących treść, co skutkowało zaniżeniem oceny dla kluczowych podstron.
Powodem było zignorowanie przez algorytm Google rel=”canonical”.
Jak więc wyeliminować zagrożenia tagu kanonicznego?
Dobrą praktyką jest dodatkowe zastosowanie atrybutów rel=”next” i rel=”prev” na stronach z paginacją (https://support.google.com/webmasters/answer/1663744?hl=pl). Implementuje się je w sekcji <head></head> w kodzie strony. Wskażą one na sekwencję logiczną stron i zwiększą szansę na poprawną indeksację i wyświetlanie użytkownikom pierwszej strony.
Możemy dodatkowo zablokować wyświetlanie się treści (np. opisu kategorii) na kolejnych stronach poza pierwszą, czy ustawić na nich „noindex, follow” w meta robots lub blokując indeksację w pliku robots.txt. Dwa ostatnie rozwiązania nie są jednak preferowane, google w klarowny sposób informuje, że blokowanie dostępu robotom nie jest właściwym rozwiązaniem.
W przypadku kiedy stronicowanie, czy sortowanie oparte jest na dodawaniu parametru do adresu url, możemy takowy parametr wykluczyć z indeksacji za pomocą GSC.
Unikalna i wartościowa treść, właściwie nasycona słowami kluczowymi jest niezaprzeczalnie jednym z istotniejszych elementów przekładających się na widoczność serwisów w wynikach wyszukiwania. Google stara się dostarczyć użytkownikom najlepiej dopasowanej odpowiedzi na ich zapytanie. Treści nieunikalne, skopiowane z innych stron lub zduplikowane w obrębie serwisu mogą jedynie utrudnić indeksację i wyrzucić nasz serwis z pierwszej dziesiątki SERP.
Samo wdrożenie rel=”canonical” na stronach paginacji może okazać się niewystarczające, dlatego warto dodatkowo zastosować atrybuty rel=”next”, rel=”prev” oraz zablokować wyświetlanie się treści na kolejnych podstronach.